
线性回归
线性回归算法思想
线性回归简介
- 定义:线性回归是一种利用回归方程对一个或多个自变量和目标值之间的关系进行拟合的建模分析方式
- 应用场景:预测连续值
- 任务目标:任务: 从样本中学习特征(如身高)和目标(如体重)之间的关系,利用这个关系预测新数据的目标值
线性回归数学表示
一元线性回归
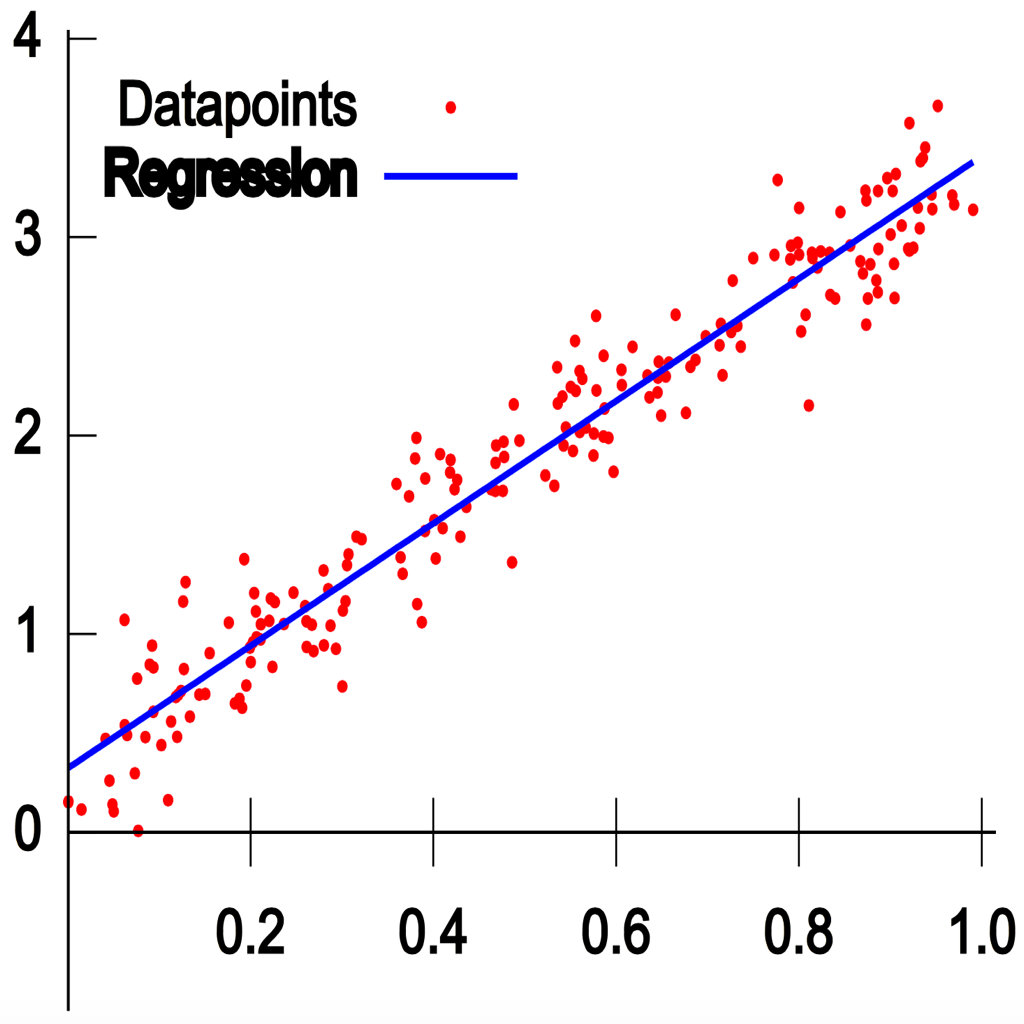
- 定义:目标值只与一个因变量有关系
- 公式:$y = kx + b$,其中k是斜率,表示特征值和标签值之间的线性关系;b是截距;x为特征值;y为目标值,至少有两个样本
- 目标:找到一条直线,使得这条直线与所有样本点的误差最小
- 方法:利用所有样本点的特征值和目标值,通过求解线性方程组来找到最佳直线
多元线性回归
- 定义: 当目标值与多个自变量有关时,使用的线性回归称为多元线性回归
- 公式:$Y=w_1x_1+w_2x_2+w_3x_3+…+b$,其中是$w_i$各个自变量的权重,表示该自变量对目标值的影响程度;b是截距
- 矩阵表示:$Y=W^TX$,其中w是权重向量,x是特征向量,w实例:$(b, w_1, w_2,…)^T$,x实例:$(1, x_1, x_2, …)^T$
权重影响
- 权重值w:权重值越大,说明对应的特征对目标值的影响越大;权重值越小,影响越小
- 特征选择:在进行特征选择时,可以根据权重值的大小来选择对目标值影响较大的特征(数据降维)
- 求解目标:线性回归的求解目标是找到最佳的权重向量W,使得预测值与实际值之间的误差最小
[!note] 线性回归
线性回归假设因变量和自变量之间存在线性关系,即使有像抛物线、指数、对数等非线性关系
线性回归问题求解
线性回归API
- 来自
sklearn的API:sklearn.linear_model.LinearRegression,- 参数
fit_intercept:表示是否计算偏置,默认True
- 参数
- 使用
model.coef_和model.intercept_获取到模型的权重w和偏置b - 实例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17from sklearn.linear_model import LinearRegression
# step 1:准备数据 (身高和体重关系)
x = [[160], [166], [172], [174], [180]]
y = [56.3, 60.6, 65.1, 68.5, 75]
# step 2: **实例化模型**
model = LinearRegression(fit_intercept=True)
# step 3: 模型训练
model.fit(x, y)
print("模型权重(weight):", model.coef_)
print("模型偏置(bias):", model.intercept_)
# step 4: 模型预测
print(model.predict([[176]]))
损失函数
损失函数概念
- 误差概念:$L = \hat y - y$,其中y表示真实值,$\hat y$表示预测值,最好的拟合使得所有点的误差最小
- 损失函数定义:衡量每个样本预测值与真实值差异的函数,又称代价函数,成本函数,目标函数,必须包含训练集中全部样本的误差,而非部分样本,最优拟合线就是使损失函数值最小的直线
- **优化方法(使loss最小)**:
- 正规方程法:解析解法,直接求得闭式解,适用于小规模数据
- 梯度下降法:迭代逼近最优解的数值方法,适用于大规模数据
- 求解方法:采用最小二乘法为例
- 列出损失函数: $L(k, b) = \sum (kx_i + b - y_i)^2$其中$x_i, y_i$均为真实值
- 先固定b计算k,变为一元二次方程,设b为0,计算出损失函数最小的k,再求出b的值
- 不建议使用最小二乘法原因:随着样本数量增多,误差会增大
回归问题中损失函数
最小二乘法(Least Square method)
- 公式:预测值与真实值之差的平方和,即$$L(k, b) = \sum_{i=1}^n (kx_i + b - y_i)^2$$
- 特点:随着样本数量增多,误差会增大
均方误差(Mean-Square Error, MSE)
- 公式:预测值与真实值之差的平方和的平均值,即$$L(w, b) = \sum_{i = 1}^{n} \frac{1}{n} (y_i - \hat{y_i})^2$$,其中n为样本个数,$y_i$为真实值,$\hat{y_i}$为预测值。
- 特点:对异常值(离群点)较为敏感,因为平方会放大差异
平均绝对误差(Mean Absolute Error, MAE)
- 公式:预测值与真实值之差的绝对值的平均值,即$$L(w, b) = \sum_{i = 1}^{n} \frac{1}{n} |y_i - \hat{y}|$$,注意此方法不方便求导
- 特点:对异常值不那么敏感,因为只考虑绝对差异,但是不方便求导
正规方程法
一元线性方程
- 已知:
- 一元线性方程:y = kx + b
- 数据集D = ${(x_1, y_1), (x_2, y_2), (x_3, y_3), …}$其中x是标量,y是标量
- 损失函数为:$L(k, b) = \sum_{i = 1}^n (\hat{y} - y)^2$
- 对k求偏导:$$\frac{\partial L(k, b)}{\partial k} = \sum_{i=1}^n(2kx^{(i)2} + 2bx^{(i)} - 2x^{(i)}y^{(i)}) = 0$$
- 对b求偏导:$$\frac{\partial L(k, b)}{\partial k} = \sum_{i=1}^n(2kx^{(i)} + 2b - 2y^{(i)}) = 0$$
带入n个样本,解上述方程,即可得到使得损失函数最小的k,b
多元线性方程(了解即可)
- 已知条件:
- 多元线性方程:$y = w_1x_1 + w_2x_2 + w_3x_3 + … = \boldsymbol{w^Tx} + b$
- 数据集D = ${(x_1, y_1), (x_2, y_2), (x_3, y_3), …}$其中x是d(d>1)维向量,y是标量,设样本数为n
- 损失函数为:$Loss = ||\boldsymbol{Xw} - y||2^2$,其中X为(n, d+1)维矩阵,w为(d+1,1)维向量,y为真实值向量(n,1),d+1维原因是因为合并$w{(d \times 1)}$和b为$w_{(d+1) \times 1}$
- 对w求导:$$\frac{\partial Loss}{\partial w} = 2(Xw - y) * X = 0$$解得$w = (X^TX)^{-1}*X^Ty$
[!warning] 正规方程法局限性
当是大规模数据集时,矩阵运算复杂,占用高内存,故正规方程法只适用于小规模数据集(n<6)
而且使用到矩阵的逆运算,只有是满秩矩阵时,才可以求逆($X^TX$应该是满秩方阵,求解答)
梯度下降法
梯度的概念
- 梯度与导数的关系:梯度为导数的方向
- 梯度和导数的方向特性:导数是函数上升最快的方向
- 梯度求解:
- 在单变量中梯度是某一点的斜率(导数),函数增长最快的方向
- 在多变量中梯度为(以f(x, y, z)为例)$$\nabla f = (\frac{\partial f}{\partial x},\frac{\partial f}{\partial y},\frac{\partial f}{\partial z}) = \frac{\partial f}{\partial x}\boldsymbol i + \frac{\partial f}{\partial y}\boldsymbol j + \frac{\partial f}{\partial z}\boldsymbol k$$方向为偏导数分量的向量方向
梯度下降法

- 梯度下降概念:沿着梯度下降的方向求解极小值
- 超参数:学习率,初始位置
- 梯度下降计算步骤:
- 输入已知参数:初始化位置S;每步距离为lr(学习率)
- 步骤1:令初始化位置为任意位置S
- 步骤2:在当前位置判断是否为极小值点
- 步骤3:寻找当前最陡下降方向,计算梯度时,$grad = \frac{F_{当前位置} - F_{样本点位置}}{x_{当前位置} - x_{样本点位置}}$
- 步骤4:沿梯度方向移动步长lr到达新位置S’
- 步骤5:在新位置重复判断过程,直到找到极小值点
- 梯度下降更新步骤:
- 已知:损失函数J,学习率lr,初始位置$S_i$,$$S_{i+1} = S_i - lr * \frac{\partial f}{\partial S_i}$$
梯度下降算法API
- 来自
sklearn的API:sklearn.linear_model.SGDRegressor,SGDRegressor类实现了随机梯度下降学习,支持不同损失函数和正则化惩罚项,来拟合回归方程- 参数
loss:损失函数类型,例如squared_loss - 参数
fit_intercept:是否计算偏置 - 参数
learning_rate:学习率策略(可选),string类型,可以配置学习率随迭代次数不断减小,默认invscaling,具体可看SGDRegressor — scikit-learn 1.7.0 documentation - 参数
eta:学习率的值
- 参数
- 使用
model.coef_和model.intercept_获取到模型的权重w和偏置b[!note] 名词解释:学习率退火
退火原理: 学习率随迭代次数增加而逐渐减小,初期:较大学习率(离最优解较远),后期:较小学习率(接近最优解),使用invscaling参数设置,学习率更新公式:$lr_{i+1} = \frac{lr_i}{pow(t, power_t)}$,其中t为迭代次数
梯度下降法的分类
批量梯度下降(BGD)
- 特点: 每次迭代使用全部样本计算梯度
- 计算量: 当样本量很大时(如十万条),计算量会非常大
- 更新速度: 由于需要计算所有样本,更新速度较慢
- 稳定性: 能保证收敛到全局最优(凸函数)或局部最优(非凸函数)
- 主要缺点:
- 计算量过大,硬件要求高
- 训练速度慢,不适合大规模数据集
- 适用场景: 小规模数据集且需要精确计算的场景
随机梯度下降(SGD)
- 特点: 每次迭代随机选择一个样本计算梯度
- 优势: 计算量小,更新速度快,内存需求小
- 问题: 容易受到异常值影响,收敛过程可能震荡,可能陷入局部最优解
- 适用场景: 样本量极大时,可以快速得到近似解
小批量梯度下降(mini-batch GD, MBGD)
- 特点: 每次迭代选择部分样本(如16条)计算梯度
- 平衡点: 介于BGD和SGD之间,既减少计算量又降低异常值影响
- 常用设置: 批量大小通常设为2的幂次
- 实际应用: 深度学习中最常用的优化方法
- 参数关系:
- batch_size=1时退化为随机梯度下降
- batch_size=n时变为全梯度下降(批量梯度下降)
随机平均梯度下降
- 核心思想:每次仍选1个样本,但使用历史梯度平均值更新参数
- 实现步骤:
- 选择样本D1,计算梯度存入列表[D1],使用列表中梯度均值更新参数
- 选择样本D2,梯度存入列表[D1,D2],使用列表中梯度均值更新参数
- 若重复选择D1,更新列表中D1的梯度值
- 用列表梯度均值更新参数
- 优势:平滑异常值影响,提高收敛稳定性
- 缺点:初期表现不佳(初始梯度设为0),需要存储历史梯度,内存消耗较大
梯度下降存在的问题
- 局部最优解:可能停留在局部极小值而非全局最小值
- 学习率问题:学习率过大,可能越过最优点,产生震荡,学习率过小,收敛速度过慢
- 精度限制:通常只能接近最优点而无法精确到达
- 初始位置选取:初始位置的选择影响收敛速度
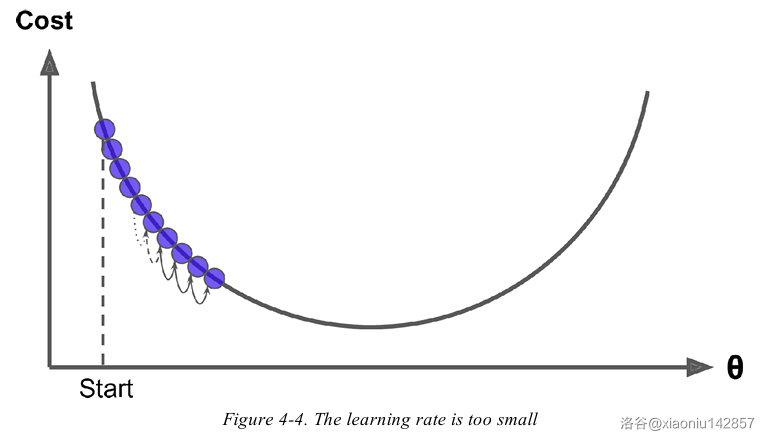
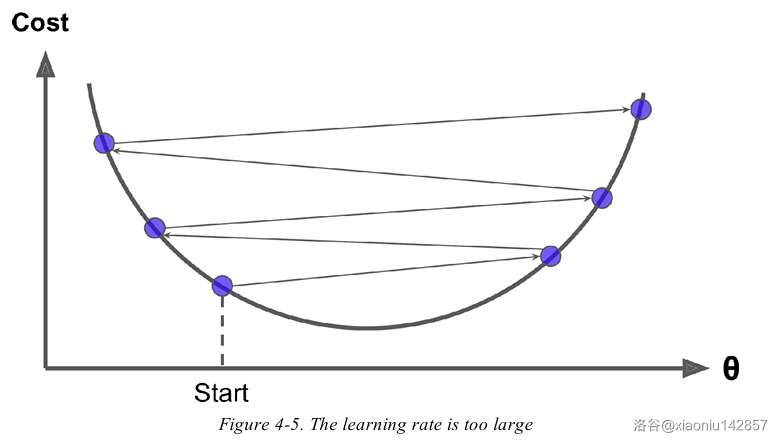
梯度下降法与正规方程法的比较
| 正规方程法 | 梯度下降法 | |
|---|---|---|
| 求解方式 | 通过求导一步到位直接求得最小值 | 通过迭代逐步逼近最小值 |
| 适用场景 | 适合简单问题 | 适合复杂、高维问题 |
| 计算效率 | 计算量可能很大(需计算矩阵逆) | 相对较小,与学习率相关 |
| 超参数 | 无 | 初始位置,学习率 |
| 结果稳定性 | 结果稳定 | 结果受学习率的影响 |
模型评估
平均绝对误差(MAE)
- 计算公式:预测值与真实值之差的绝对值的平均值,即$$MAE = \sum_{i = 1}^{n} \frac{1}{n} |y_i - \hat{y}|$$
- API调用:
sklearn.metrics.mean_absolute_error - 特点:对异常值不敏感,给出平均误差水平
均方误差(MSE)
- 计算公式:预测值与真实值之差的平方和的平均值,即$$MSE = \sum_{i = 1}^{n} \frac{1}{n} (y_i - \hat{y_i})^2$$
- API调用:
sklearn.metrics.mean_squared_error - 特点:放大较大误差的影响,对所有误差平等对待
均方根误差(Root Mean Square Error, RMSE)
- 计算公式:预测值与真实值之差的平方和的平均值开方,即$$RMSE = \sqrt{\sum_{i = 1}^{n} \frac{1}{n} (y_i - \hat{y_i})^2} = \sqrt{MSE}$$
- API调用:
None(sklearn未给出) - 特点:量纲与原始数据一致,解释性更好,对异常值更敏感,过拟合提示,RMSE过小可能提示模型过度拟合噪声(异常点)
[!note] 三种损失函数使用建议
一般优先使用MAE和RMSE,MAE反应真实误差,RMSE会放大误差点,RMSE值异常降低时要警惕过拟合,通常RMSE > MAE(平方放大效应)例如:MAE:(3 + 1) /2= 2,RMSE:$\sqrt{(3^2+1^2)/2}=\sqrt{5}$
欠拟合与过拟合
欠拟合与过拟合概念
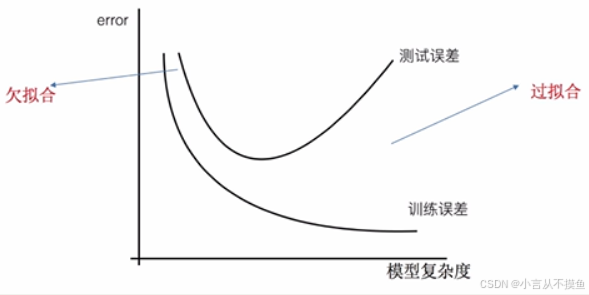
- 测试误差的最低点为正好拟合。
- 欠拟合概念:
- 核心特征:模型在训练集和测试集上表现都不好
- 模型状态:模型过于简单,无法捕捉数据特征
- 误差表现:训练误差和测试误差都较大
- 泛化能力:欠拟合时模型未学到有效特征
- 过拟合概念:
- 核心特征:模型偏差小,方差大,只在训练集上表现好
- 模型状态:参数过多或者结构过于复杂的统计模型
- 误差表现:训练误差小但测试误差大
- 泛化能力:过拟合时泛化能力差
欠拟合和过拟合出现原因及其解决方法
- 欠拟合出现原因:
- 特征不足:模型学到的特征太少,导致无法充分描述数据规律
- 模型简单:使用过于简单的模型(如线性模型)时,模型容量不足以捕捉数据中的复杂关系
- 欠拟合解决方法:
- 添加新特征:通过组合、泛化或相关性分析增加特征
- 模型升级:更换为容量更大的复杂模型
- 过拟合出现原因:
- 模型复杂:模型过于复杂,学习了数据中的噪声和异常值
- 数据问题:训练数据量过少或包含过多异常值
- 过拟合解决方法
- 清洗数据:对异常点数据,数据不纯的地方进行清洗
- 增加数据量:对原始数据训练过头,增加新的数据缓解过拟合
- 正则化:L1正则化,L2正则化
- 减少特征维度:特征太多,样本数量太少,导致学习不充分,泛化能力差,如PCA
[!note] 解决方法选取
正则化是实际工作中最常用的解决方案,尤其当数据收集困难时,且L2使用频率大于L1
欠拟合和过拟合实例
- 欠拟合:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47import matplotlib
import matplotlib.pyplot as plt
import numpy as np
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
matplotlib.use('TkAgg')
'''欠拟合实例'''
# 生成数据
np.random.seed(0)
x = np.random.uniform(-3, 3, size=100)
x = np.sort(x) # 生成有序数组方便绘图
y = 2 * x ** 2 + 3 * x + np.random.normal(0, 3, size=100)
# 模型训练
x = x.reshape(-1, 1)
model = LinearRegression()
model.fit(x, y)
# 模型预测
y_pred = model.predict(x)
print(f"欠拟合误差:{mean_squared_error(y, y_pred)}")
# 展示数据
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.title("underfit")
plt.plot(x, y_pred, color='red')
plt.scatter(x, y)
'''解决方法'''
# 增加特征
x2 = np.hstack([x, x**2]) # 已知存在二次方项的特征时,增加二次方项特征,现在特征个数为2
model = LinearRegression()
model.fit(x2, y)
# 模型预测
y_pred = model.predict(x2)
print(f"添加特征x^2之后:{mean_squared_error(y, y_pred)}")
# 数据展示
plt.subplot(1, 2, 2)
plt.title("add feature x^2")
plt.plot(x, y_pred, color="red")
plt.scatter(x, y)
plt.show(block=True)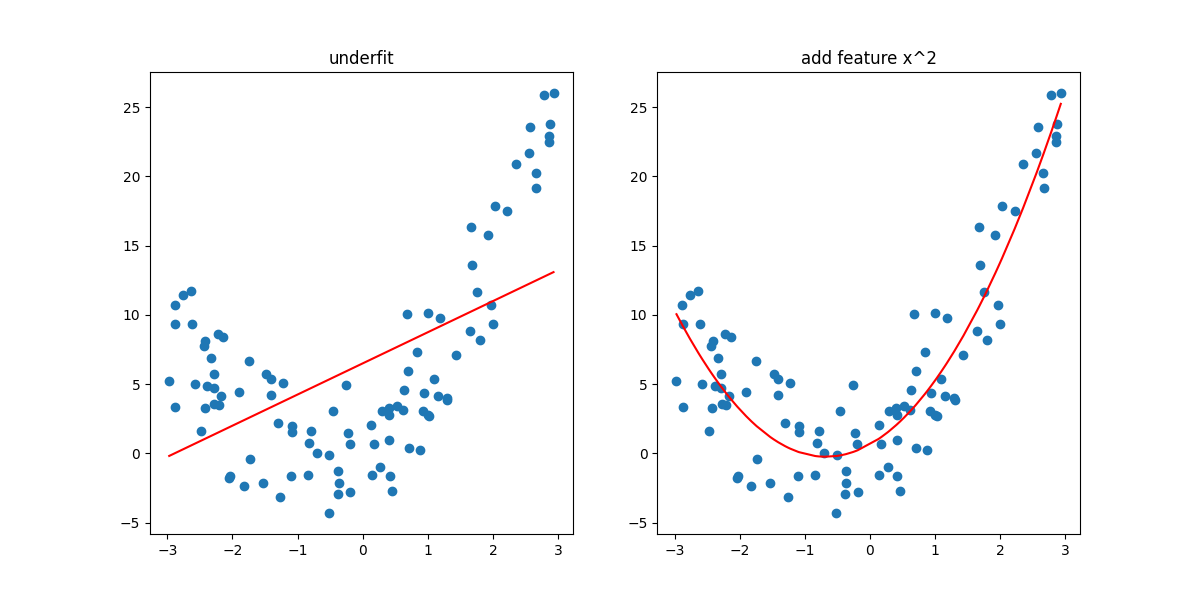
- 过拟合:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51# 复制欠拟合代码
'''过拟合'''
# 增加特征
x3 = np.hstack([x, x**2, x**3, x**4, x**5, x**6, x**8, x**10]) # 增加更多次方
model = LinearRegression()
model.fit(x3, y)
# 模型预测
y_pred = model.predict(x3)
print(f"过拟合:{mean_squared_error(y, y_pred)}")
# 数据展示
plt.figure(figsize=(12, 4))
plt.subplot(1, 3, 1)
plt.title("overfit")
plt.plot(x, y_pred, color="red")
plt.scatter(x, y)
'''L1正则化'''
from sklearn.linear_model import Lasso
# 模型定义
model = Lasso(alpha=0.1)
model.fit(x3, y)
# 模型预测
y_pred = model.predict(x3)
print(f"Lasso回归:{mean_squared_error(y, y_pred)}")
# 数据展示
plt.subplot(1, 3, 2)
plt.title("Lasso Regression")
plt.plot(x, y_pred, color="red")
plt.scatter(x, y)
'''L2正则化'''
from sklearn.linear_model import Ridge
model = Ridge(alpha=0.1)
model.fit(x3, y)
# 模型预测
y_pred = model.predict(x3)
print(f"Ridge回归:{mean_squared_error(y, y_pred)}")
# 数据展示
plt.subplot(1, 3, 3)
plt.title("Ridge Regression")
plt.plot(x, y_pred, color="red")
plt.scatter(x, y)
plt.show(block=True)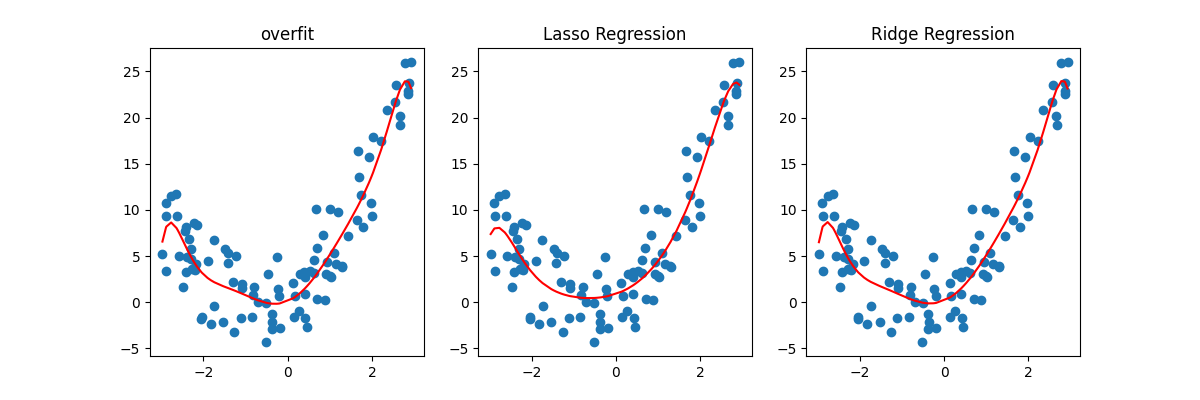
正则化
- 概念:在模型训练时,数据中有些特征影响模型复杂度,或者某个特征的异常值较多,要减少该特征的影响
- 如何消除异常值带来的对w的影响:在损失函数中添加正则化项
L1正则化
- 定义:在损失函数中添加L1范数作为正则化项,公式为$$J(w) = Loss(w) + \alpha * \sum_{i=1}^n |w_i|$$
- 超参数:惩罚系数(正则化系数)$\alpha$,控制正则化强度,值越大惩罚力度越大
- 作用原理:通过绝对值函数的梯度特性(x>0导数为1,x<0导数为-1)迫使权重趋向0,可能使不重要的特征权重精确等于0,实现特征筛选
- Lasso回归模型:线性回归 + L1正则化
L2正则化
- 定义:在损失函数中添加L1范数作为正则化项,公式为$$J(w) = Loss(w) + \alpha * \sum_{i=1}^n w_i^2$$
- 超参数:惩罚系数(正则化系数)$\alpha$,控制正则化强度,值越大惩罚力度越大
- 作用原理:同L1正则化,但是会使不重要特征的权重趋近于0但不等于0,且对异常值的鲁棒性更好,整体压缩权重幅度,降低模型复杂度
- Ridge回归模型:L2正则化 + 线性回归模型
案例(波士顿房价)
- 数据来自: 波士顿房价
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48from sklearn.preprocessing import StandardScaler # 特征预处理,正则化
from sklearn.model_selection import train_test_split # 划分数据集
from sklearn.linear_model import LinearRegression # 正规方程回归模型
from sklearn.linear_model import SGDRegressor # 梯度下降回归模型
from sklearn.metrics import mean_squared_error # 均方误差损失函数
import pandas as pd
import numpy as np
# 加载数据
def load_boston():
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None)
data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])
target = raw_df.values[1::2, 2]
return data, target
data, target = load_boston()
# 数据集划分
x_train, x_test, y_train, y_test = train_test_split(data, target, test_size=0.2, random_state=0)
# 标准化
process = StandardScaler()
x_train = process.fit_transform(x_train)
x_test = process.fit(x_test)
# 模型训练
model = LinearRegression(fit_intercept=True)
model.fit(x_train)
print(model.coef_)
print(model.intercept_)
# or
model = SGDRegressor(fit_intercept=True)
model.fit(x_train)
print(model.coef_)
print(model.intercept_)
# 模型预测
y_pred = model.predict(x_test)
# 模型评估
metric = mean_squared_error(y_test, y_pred)
print(metric)
参考资料
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 LinHao's Pages!


