
逻辑回归
数学基础
sigmoid激活函数
- 数学公式:$$f(x) = \frac{1}{1 + e^{-x}}$$
- 核心作用:将线性回归输出的$(-\infty, +\infty)$映射到(0, 1),将输出映射到概率值
极大似然估计
- 核心思想:跟据观测值和结果来估计模型算法的未知参数,极大似然估计是在统计观测值情况下,参数最有可能的结果
- 注意:极大似然函数不可以直接作为损失函数,需要加入负号转化为求最小值,在逻辑回归中,通过对数似然函数加负号构建损失函数
逻辑回归算法思想
逻辑回归基本思想
- 核心用途:主要用于分类任务,用于解决二分类任务,多分类任务要套用多个逻辑回归模型
- 基本结构:在线性回归之后接激活函数,将连续输出变为概率值(0~100%)
- 计算流程:
- 通过线性模型$f(x) = w^T x + b$计算特征加权值
- 使用sigmoid函数将线性输出映射为概率值
- 逻辑回归假设函数:$h(w) = sigmoid(w^Tx + b)$
- 优化方法:梯度下降算法
逻辑回归中的损失函数
- 函数定义:交叉熵损失函数$$Loss(w) = -\sum_{i=1}^m(y_ilog(p_i) + (1-y_i)log(1-p_i))$$,其中$y_i$表示真实值,取值0或1,$p_i$表示预测值,取值[0, 1]
- 函数特性:
- 当真实值为1时,原式变为$Loss=-log(p_i)$,则$p_i$越靠近1时,损失越小
- 当真实值为0时,原式变为$Loss=-log(1-p_i)$,则$p_i$越靠近0时,损失越小
- 函数本质:有极大似然函数,去对数,填符号,转化而来
- 设有n个样本,则极大似然函数为$J = \prod_{i=1}^np^{y_i}(1-p)^{1-y_i}$
- 取极大似然函数对数为$logJ = \sum_{i=1}^{n}(y_ilog(p_i) + (1-y_i)log(1 - p_i))$
- 加负号变为交叉熵损失函数
逻辑回归的API
- 来自
sklearn的API:sklearn.linear_model.LogisticRegression(solver=liblinear, penalty='l2', C=1.0)- 参数
solver:是优化方法,可选liblinear对小数据集场景训练速度快,sag和saga对大数据集更快,其中saga和sag支持L2正则化或没有正则化,liblinear和saga支持L1正则化 - 参数
penalty:正则化种类,可选l1或l2 - 参数
C:正则化力度,相当于正则化项前的系数$\alpha$ - 注意:默认将类别数量少的作为正例(标签为1)
- 参数
- 实例:
1
2model = LogisticRegression()
model.fit(x_train, y_train)
分类任务评估指标
混淆矩阵(Confusion Matrix)
- 应用场景:针对不同场景需求(如希望正样本全部被检测或负样本全部被检测)设计不同的评估指标
- 评估指标:
- **真正例(TP)**:真实值为正例的样本中,被划分为正例的数量
- **伪反例(FN)**:真实值为正例的样本中,被划分为反例的数量
- **伪正例(FP)**:真实值为反例的样本中,被划分为正例的数量
- **真反例(TN)**:真实值为反例的样本中,被划分为反例的数量
- 矩阵结构:
| 预测正例(Prediction Positive) | 预测假例(Prediction Negative) | |
|---|---|---|
| 真实正例(Reference Positive) | 真正例TP(true positive) | 伪反例FN(false negative) |
| 真实假例(Reference Negative) | 伪正例FP(false postive) | 真反例TN(true negative) |
- 混淆矩阵API:来自
sklearn的API:sklearn.metrics.confusion_matrix- 参数
labels:指明正负样本 第一个参数为正样本,第二个参数为负样本 - 参数
y_true:真实标签列表 - 参数
y_pred:预测结果列表
- 参数
- 实例:
1
2
3
4
5
6
7
8
9
10
11from sklearn.metrics import confusion_matrix
import pandas as pd
# 构建数据: 真实值, 预测值
y_true = ['恶性', '恶性', '恶性', '恶性', '恶性', '恶性', '良性', '良性', '良性', '良性']
y_pred = ['恶性', '恶性', '恶性', '良性', '良性', '良性', '良性', '良性', '良性', '良性']
# 混淆矩阵
matrix = confusion_matrix(y_true, y_pred, labels=['恶性', '良性']) # 其中labels参数指明正负样本 第一个参数为正样本,第二个参数为负样本
DF = pd.DataFrame(matrix, columns=["恶性", "良性"], index=["恶性", "良性"])
print(DF)
精确率(Accuracy)
- 定义:预测正确的数量占比
- 数学公式:$$Accuracy = \frac{TP+TN}{TP+FN+FP+TN}$$
查准率(Precision)
- 定义:预测为正例的样本中实际为正例的比例,又称精确率
- 数学公式:$$Precision = \frac{TP}{TP + FP}$$
- 查准率API:来自
sklearn的sklearn.metrics.precision_score- 参数
y_true:真实标签列表 - 参数
y_pred:预测结果列表 - 参数
pos_label:正样本标签
- 参数
- 实例:
1
2
3
4
5
6
7
8
9from sklearn.metrics import precision_score
import pandas as pd
# 构建数据: 真实值, 预测值
y_true = ['恶性', '恶性', '恶性', '恶性', '恶性', '恶性', '良性', '良性', '良性', '良性']
y_pred = ['恶性', '恶性', '恶性', '良性', '良性', '良性', '良性', '良性', '良性', '良性']
# 精确率
print(precision_score(y_true, y_pred, pos_label='恶性'))
召回率(recall)
- 定义:表示在真实为正例的样本中,被正确预测为正例的比例,又称查全率
- 数学公式:$$Recall = \frac{TP}{TP + FN}$$
- 召回率API:来自
sklearn的sklearn.metrics.recall_score- 参数
y_true:真实标签列表 - 参数
y_pred:预测结果列表 - 参数
pos_label:正样本标签
- 参数
- 实例:
1
2
3
4
5
6
7
8
9from sklearn.metrics import recall_score
import pandas as pd
# 构建数据: 真实值, 预测值
y_true = ['恶性', '恶性', '恶性', '恶性', '恶性', '恶性', '良性', '良性', '良性', '良性']
y_pred = ['恶性', '恶性', '恶性', '良性', '良性', '良性', '良性', '良性', '良性', '良性']
# 精确率
print(recall_score(y_true, y_pred, pos_label='恶性'))[!note] 召回率和精确率的关系
召回率和精确率是对抗关系,召回率高时,精确率会变低
F1-score
- 定义:综合精确率和召回率的评估指标,适用于需要平衡两者的情况,精确率和召回率通常难以同时达到最高,F1-score提供平衡视角
- 数学公式: $$F1 = \frac{2 * Precision * Recall}{Precision + Recall}$$
- F1-score的API:来自
sklearn的sklearn.metrics.f1_score- 参数
y_true:真实标签列表 - 参数
y_pred:预测结果列表 - 参数
pos_label:正样本标签
- 参数
- 实例:
1
2
3
4
5
6
7
8
9from sklearn.metrics import f1_score
import pandas as pd
# 构建数据: 真实值, 预测值
y_true = ['恶性', '恶性', '恶性', '恶性', '恶性', '恶性', '良性', '良性', '良性', '良性']
y_pred = ['恶性', '恶性', '恶性', '良性', '良性', '良性', '良性', '良性', '良性', '良性']
# 精确率
print(f1_score(y_true, y_pred, pos_label='恶性'))
ROC曲线
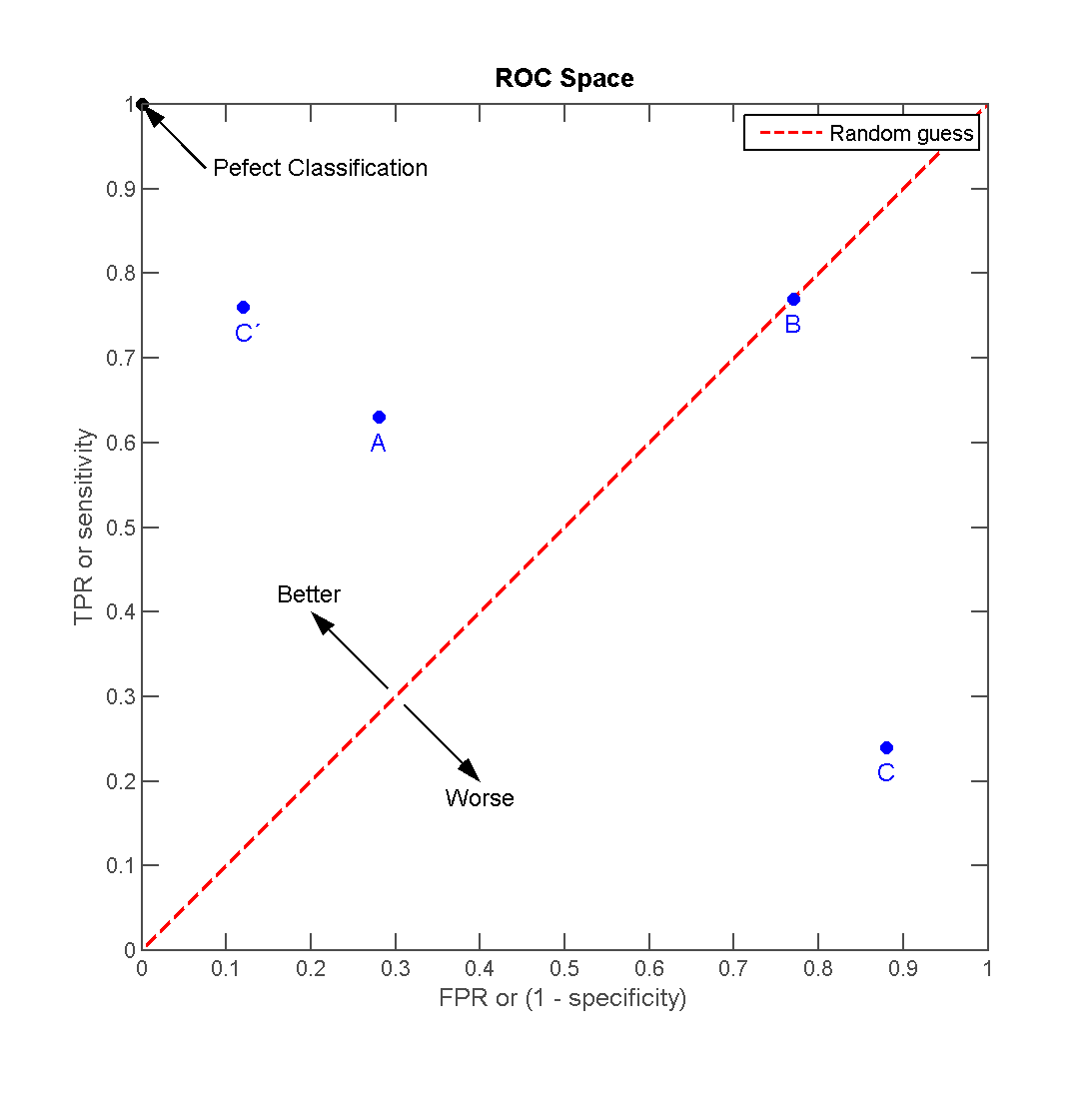
- 基础概念:
- 真正率(True Postive Rate, TPR):正样本中被预测为正样本的比例,数学公式为$TPR = \frac{TP}{TP + FN}$
- 假正率(False Positive Rate, FPR):负样本中被预测为正样本的比例,数学公式为$FPR = \frac{FP}{FP + TN}$
- ROC曲线构成为:x轴为FPR,y轴为TPR
- 判断标准:TPR越大,FPR越小,则模型性能越好,模型的ROC曲线在RandomGuess曲线(对角线表示随机猜测的性能)上方时,表明模型是可取的,在其下方时表明模型无效
- 曲线特征:
- 曲线必经过(0,0)和(1,1)两点
- 曲线越靠近左上角(0,1)点,模型性能越好
- 对角线表示随机猜测的性能
- 特殊点含义:
- 点(0, 0):FPR = 0,TPR = 0,表示所有负样本预测正确,所有正样本预测错误
- 点(1, 0):FPR = 1, TPR = 0, 表示所有负样本预测错误,所有正样本预测错误
- 点(0, 1):FPR = 0, TPR = 1, 表示所有负样本预测正确,所有正样本预测正确
- 点(1, 1):FPR = 1, TPR = 1, 表示所有负样本预测错误,所有正样本预测正确
AUC指标
- AUC(Aera Under the ROC Curve)定义:ROC曲线与x轴所围成面积
- 判断标准:
- AUC=1表示完美分类器
- AUC=0.5表示模型没有区分能力
- AUC>0.5表示模型优于随机猜测
案例
癌症实例分析
1 | # 0.导入库函数 |
参考资料
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 LinHao's Pages!


